仿Kafka实现的JAVA版时间轮算法
从 2 个面试题说起,第一个问题: 如果一台机器上有 10w 个定时任务,如何做到高效触发?
具体场景是:
有一个 APP 实时消息通道系统,对每个用户会维护一个 APP 到服务器的 TCP 连接,用来实时收发消息,对这个 TCP 连接,有这样一个需求:“如果连续 30s 没有请求包(例如登录,消息,keepalive 包),服务端就要将这个用户的状态置为离线”。
其中,单机 TCP 同时在线量约在 10w 级别,keepalive 请求包较分散大概 30s 一次,吞吐量约在 3000qps。
怎么做?
常用方案使用 time 定时任务,每秒扫描一次所有连接的集合 Map<uid, last_packet_time>,把连接时间(每次有新的请求更新对应连接的连接时间)比当前时间的差值大 30s 的连接找出来处理。
另一种方案,使用环形队列法: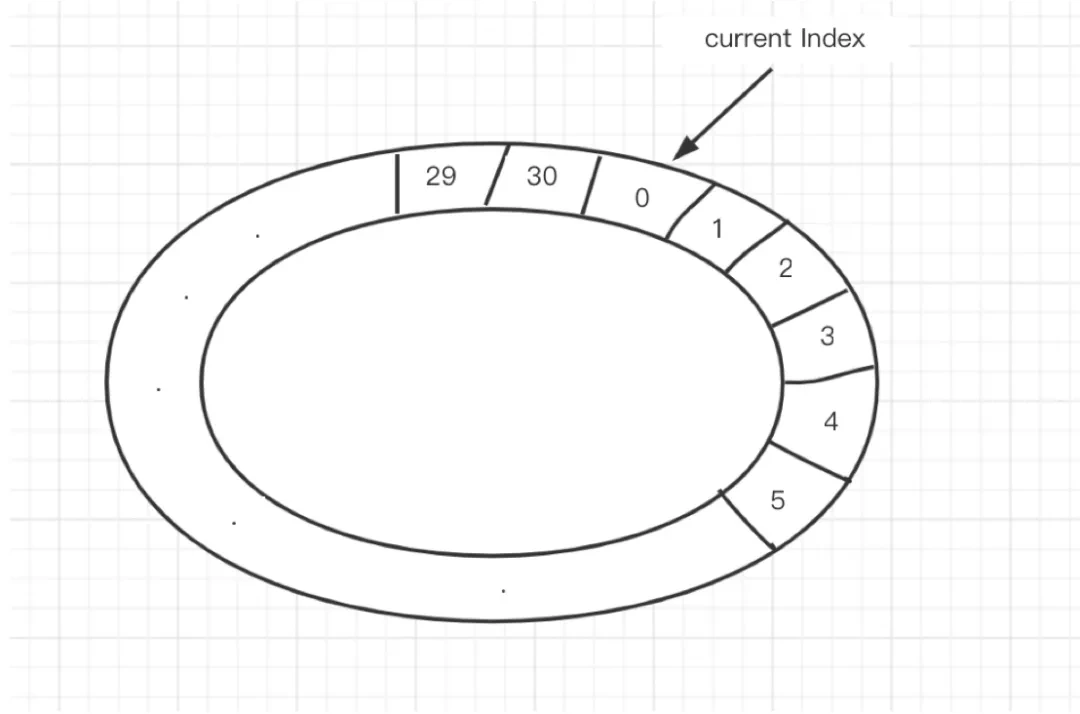
三个重要的数据结构:
30s 超时,就创建一个 index 从 0 到 30 的环形队列(本质是个数组)
环上每一个 slot 是一个 Set
同时还有一个 Map<uid, index>,记录 uid 落在环上的哪个 slot 里
这样当有某用户 uid 有请求包到达时:
从 Map 结构中,查找出这个 uid 存储在哪一个 slot 里
从这个 slot 的 Set 结构中,删除这个 uid
将 uid 重新加入到新的 slot 中,具体是哪一个 slot 呢 => Current Index 指针所指向的上一个 slot,因为这个 slot,会被 timer 在 30s 之后扫描到
更新 Map,这个 uid 对应 slot 的 index 值
哪些元素会被超时掉呢?
Current Index 每秒种移动一个 slot,这个 slot 对应的 Set
所以,当没有超时时,Current Index 扫到的每一个 slot 的 Set 中应该都没有元素。
两种方案对比:
方案一每次都要轮询所有数据,而方案二使用环形队列只需要轮询这一刻需要过期的数据,如果没有数据过期则没有数据要处理,并且是批量超时,并且由于是环形结构更加节约空间,这很适合高性能场景。
第二个问题: 在开发过程中有延迟一定时间的任务要执行,怎么做?
如果不重复造轮子的话,我们的选择当然是延迟队列或者 Timer。
延迟队列和在 Timer 中增 加延时任务采用数组表示的最小堆的数据结构实现,每次放入新元素和移除队首元素时间复杂度为 O(nlog(n))。
时间轮
方案二所采用的环形队列,就是时间轮的底层数据结构,它能够让需要处理的数据(任务的抽象)集中,在 Kafka 中存在大量的延迟操作,比如延迟生产、延迟拉取以及延迟删除等。Kafka 并没有使用 JDK 自带的 Timer 或者 DelayQueue 来实现延迟的功能,而是基于时间轮自定义了一个用于实现延迟功能的定时器(SystemTimer)。JDK 的 Timer 和 DelayQueue 插入和删除操作的平均时间复杂度为 O(nlog(n)),并不能满足 Kafka 的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为 O(1)。时间轮的应用并非 Kafka 独有,其应用场景还有很多,在 Netty、Akka、Quartz、Zookeeper 等组件中都存在时间轮的踪影。
时间轮的数据结构
参考下图,Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList 是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务 TimerTask。在 Kafka 源码中对这个 TimeTaskList 是用一个名称为 buckets 的数组表示的,所以后面介绍中可能 TimerTaskList 也会被称为 bucket。

针对上图的几个名词简单解释下:
tickMs: 时间轮由多个时间格组成,每个时间格就是 tickMs,它代表当前时间轮的基本时间跨度。
wheelSize: 代表每一层时间轮的格数
interval: 当前时间轮的总体时间跨度,interval=tickMs × wheelSize
startMs: 构造当层时间轮时候的当前时间,第一层的时间轮的 startMs 是 TimeUnit.NANOSECONDS.toMillis(nanoseconds()),上层时间轮的 startMs 为下层时间轮的 currentTime。
currentTime: 表示时间轮当前所处的时间,currentTime 是 tickMs 的整数倍(通过 currentTime=startMs - (startMs % tickMs 来保正 currentTime 一定是 tickMs 的整数倍),这个运算类比钟表中分钟里 65 秒分钟指针指向的还是 1 分钟)。currentTime 可以将整个时间轮划分为到期部分和未到期部分,currentTime 当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的 TimerTaskList 的所有任务。
时间轮中的任务存放
若时间轮的 tickMs=1ms,wheelSize=20,那么可以计算得出 interval 为 20ms。初始情况下表盘指针 currentTime 指向时间格 0,此时有一个定时为 2ms 的任务插入进来会存放到时间格为 2 的 TimerTaskList 中。随着时间的不断推移,指针 currentTime 不断向前推进,过了 2ms 之后,当到达时间格 2 时,就需要将时间格 2 所对应的 TimeTaskList 中的任务做相应的到期操作。此时若又有一个定时为 8ms 的任务插入进来,则会存放到时间格 10 中,currentTime 再过 8ms 后会指向时间格 10。如果同时有一个定时为 19ms 的任务插入进来怎么办?新来的 TimerTaskEntry 会复用原来的 TimerTaskList,所以它会插入到原本已经到期的时间格 1 中。总之,整个时间轮的总体跨度是不变的,随着指针 currentTime 的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在 currentTime 和 currentTime+interval 之间。
时间轮的升降级
如果此时有个定时为 350ms 的任务该如何处理?直接扩充 wheelSize 的大小么?Kafka 中不乏几万甚至几十万毫秒的定时任务,这个 wheelSize 的扩充没有底线,就算将所有的定时任务的到期时间都设定一个上限,比如 100 万毫秒,那么这个 wheelSize 为 100 万毫秒的时间轮不仅占用很大的内存空间,而且效率也会拉低。Kafka 为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。
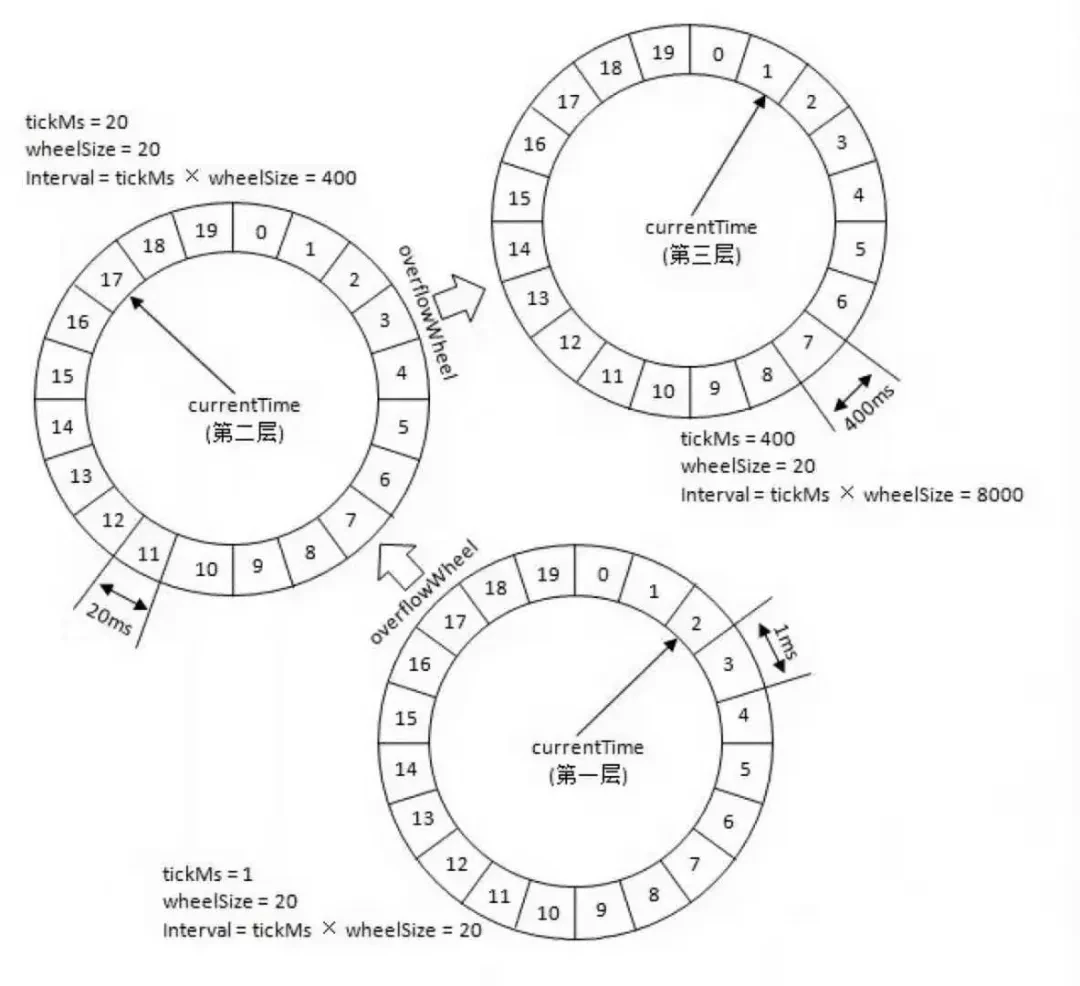
参考上图,复用之前的案例,第一层的时间轮 tickMs=1ms, wheelSize=20, interval=20ms。第二层的时间轮的 tickMs 为第一层时间轮的 interval,即为 20ms。每一层时间轮的 wheelSize 是固定的,都是 20,那么第二层的时间轮的总体时间跨度 interval 为 400ms。以此类推,这个 400ms 也是第三层的 tickMs 的大小,第三层的时间轮的总体时间跨度为 8000ms。
刚才提到的 350ms 的任务,不会插入到第一层时间轮,会插入到 interval=20*20 的第二层时间轮中,具体插入到时间轮的哪个 bucket 呢?先用 350/tickMs(20)=virtualId(17),然后 virtualId(17) %wheelSize (20) = 17,所以 350 会放在第 17 个 bucket。如果此时有一个 450ms 后执行的任务,那么会放在第三层时间轮中,按照刚才的计算公式,会放在第 0 个 bucket。第 0 个 bucket 里会包含[400,800)ms 的任务。随着时间流逝,当时间过去了 400ms,那么 450ms 后就要执行的任务还剩下 50ms 的时间才能执行,此时有一个时间轮降级的操作,将 50ms 任务重新提交到层级时间轮中,那么此时 50ms 的任务根据公式会放入第二个时间轮的第 2 个 bucket 中,此 bucket 的时间范围为[40,60)ms,然后再经过 40ms,这个 50ms 的任务又会被监控到,此时距离任务执行还有 10ms,同样将 10ms 的任务提交到层级时间轮,此时会加入到第一层时间轮的第 10 个 bucket,所以再经过 10ms 后,此任务到期,最终执行。
整个时间轮的升级降级操作是不是很类似于我们的时钟? 第一层时间轮 tickMs=1s, wheelSize=60,interval=1min,此为秒钟;第二层 tickMs=1min,wheelSize=60,interval=1hour,此为分钟;第三层 tickMs=1hour,wheelSize 为 12,interval 为 12hours,此为时钟。而钟表的指针就对应程序中的 currentTime,这个后面分析代码时候会讲到(对这个的理解也是时间轮理解的重点和难点)。
任务添加和驱动时间轮滚动核心流程图

 wechat
wechat alipay
alipay




