布隆过滤器原理及使用
什么是布隆过滤器?
我们来看这么一个场景:目标网站有上千万个URL,如何判断某个URL是否已经访问过?
使用DB存储的话,就是把每个URL存入DB,然后每次访问URL前执行
1 | slect id from table where url = 'xxxx' |
但随着URL数据量增多,每次请求前都要访问DB一次,效率非常低。当然,也可以用redis的set结构存储URL,优于DB存储,但也同样存在一个问题:耗费内存过多。
如何解决?布隆过滤器!
布隆过滤器从本质上讲是一个位数组,位数组就是数组的每个元素都只占用1bit。每个元素只能是0或者1。这样申请一个10000个元素的位数组只占用 10000/8 = 1250B 的空间。布隆过滤器除了一个位数组,还有K个哈希函数。当一个元素加入布隆过滤器的时候,会进行如下操作:
- 使用K个哈希函数对元素值进行K次计算,得到K个哈希值。
- 根据得到的哈希值,在数组中把对应下标的值设置为1。
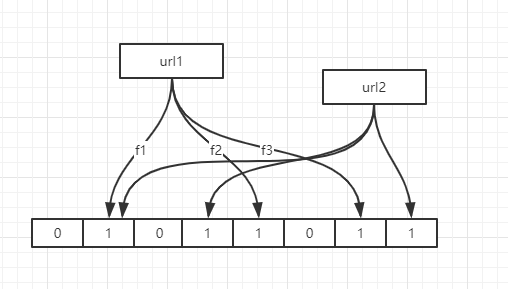
如上图:
url1通过f1,f2,f3 三个哈希函数计算得到3个值,把数组中的三个位置设置为1。
要判断一个值是否存在,则只需对元素值进行哈希计算,得到值后判断数组中的对应元素是否都为1,如果都为1,则说明这个值存在;如果存在一个值不为1,说明该元素不存在。
是不是很简单,但有没发现当数据原来越多,数组中的位置为1的也越来越多,当一个不存在的元素,经过hash运算后,得到的值在数组中查询,有可能都为1(hash碰撞),这就出现了误判。但如果布隆过滤器判断不存在过滤器中,那么这个值一定不存在布隆过滤器中。简单来说:
- 布隆过滤器说元素存在,可能会被误判。
- 布隆过滤器说元素不存在,那么一定不存在。
如何使用布隆过滤器?
这里主要讲在redis中使用布隆过滤器,当然guava也有对应用法,自行搜索。redis在4.0的版本加入了module功能,布隆过滤器可以通过module的形式添加到redis中,安装教程,我这里使用docker来体验布隆过滤器。
控制台使用布隆过滤器
1 | docker pull redislabs/rebloom |
redis 布隆过滤器主要就两个命令:
1 | // 添加元素到布隆过滤器中 |
上面说的布隆过滤器存在误判的情况,在redis中有两个值决定过滤器的准确率:
- error_rate :允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size :布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
使用命令设置:
1 | bf.reserve urls 0.01 100 |
在Java中使用布隆过滤器
引入依赖
1 | // https://github.com/RedisLabs/JReBloom |
1 | // BloomFilterTest.java |
注意事项
布隆过滤器的initial_size估计的过大,所需要的空间就越大,会浪费空间,估计的过小会影响准确率,因此在使用前一定要估算好元素数量,还需要加上一定的冗余空间以避免实际元素高出预估数量造成误差过大。
布隆过滤器的error_rate越小,所需要的空间就会越大,对于不需要过于准确的,error_rate设置的稍大一点也无所谓。
 wechat
wechat alipay
alipay




