图解 Java 虚拟机系列(一)字节码文件结构
我们都知道 .java 文件在执行之前会编译成 .class 文件后再执行。比如下面的代码:
1 | package com.jeanboy.jvm; |
在 控制台 执行下面命令:
$ cd JVMTraning/src/main/java/com.jeanboy.jvm/
$ javac HelloWorld
在 HelloWorld.java 的同级目录下会看到创建了一个 HelloWorld.class 文件。
将 HelloWorld.class 文件用 16 进制编辑器打开,可以看到如下内容: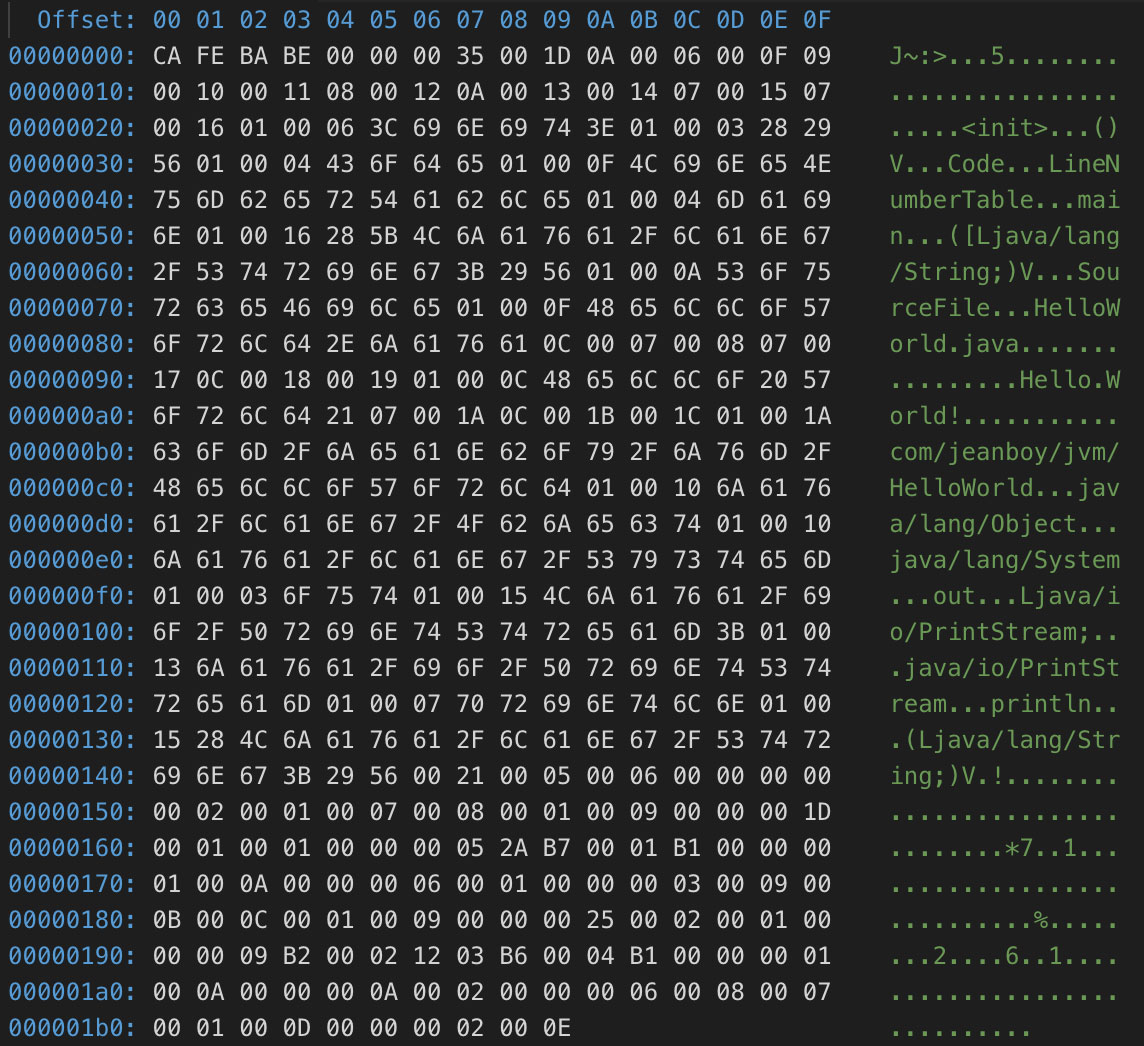
ClassFile 结构
每个 class 文件对应一个如下所示的 ClassFile 结构。
1 | ClassFile { |
class 文件是一组以 8 位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在 class 文件之中,中间没有添加任何分隔符。
根据 Java 虚拟机规范的规定,class 文件格式采用一种类似于 C 语言的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表。
无符号数属于基础数据类型,以 u1、u2、u4、u8 来分别代表 1 个字节、2 个字节、4 个字节和 8 个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成的字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据结构,所有表都习惯性地以 _info 结尾。表用于描述有层次关系的复合结构的数据,整个 class 文件本质上就是一张表。
魔数
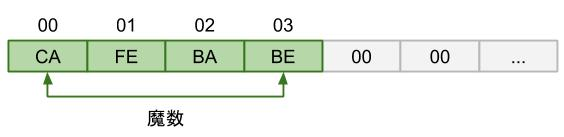
可以看到开头的 4 个字节的十六进制表示为 0xCAFEBABE,class 文件的开头这 4 个字节就是魔数(Magic Number)。它的作用就是确定这个文件是否是能被虚拟机接受的 class 文件。魔数值固定为 0xCAFEBABE,不会改变。
1 | ClassFile { |
文件版本号
紧接着魔数的 4 个字节存储的是 class 文件的版本号,第 5 和第 6 个字节是副版本号 (Minor Version),第 7 和第 8 个字节是主版本号 (Major Version)。
Java 的版本号是从 45 开始的,JDK 1.1 之后的每个 JDK 大版本发布主版本号向上加 1(JDK 1.0 ~ 1.1 使用了 45.0 ~ 45.3 的版本号),高版本的 JDK 能向下兼容以前的版本的 class 文件,但不能运行以后版本的 class 文件,即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的 class 文件。
下表是主流 JDK 版本编译器输出的默认和可支持的 class 文件版本号。
| JDK 版本号 | class 版本号 | 16 进制 |
|---|---|---|
| 1.1 | 45.0 | 002D |
| 1.2 | 46.0 | 002E |
| 1.3 | 47.0 | 002F |
| 1.4 | 48.0 | 0030 |
| 1.5 | 49.0 | 0031 |
| 1.6 | 50.0 | 0032 |
| 1.7 | 51.0 | 0033 |
| 1.8 | 52.0 | 0034 |
| 1.9 | 53.0 | 0035 |
可以看到我当前使用的 JDK 1.9.0 编译的 class 文件。

1 | ClassFile { |
常量池计数器
紧接着主次版本号之后的是常量池入口,常量池可以理解为 class 文件的资源仓库。常量池中常量的数量是不固定的,class 文件的第 9 和第 10 字节为常量池的数量。

1 | ClassFile { |
0x001D = 29 What?有 29 个常量?可是上面我们只写了个 Hello World 啊!可以使用 javap 命令看一下常量池中都有什么。
$ javap -v HelloWorld.class
可以看到如下内容:
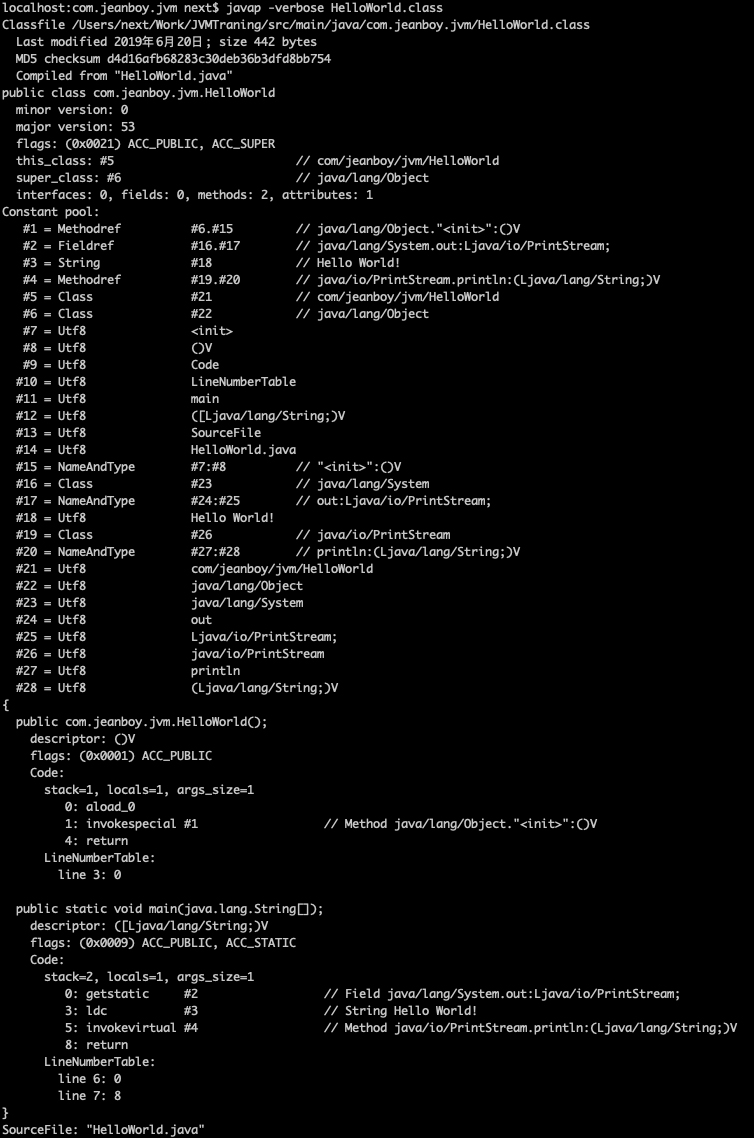
其中 Constant pool 下面的内容就是常量池里面的常量,可以看到有 28 个。
为什么 class 文件中显示的是 29 呢?
这是因为常量池计数器是从 1 开始计数的,而不是从 0 开始的。如果常量池计数器的值为 29,则后面的常量项的个数就为 28。
在制定 class 文件规范的时候,将第 0 项常量空出来是为了表达「不引用任何一个常量」的意思。
常量池
常量池中主要存放两大常量:字面量(Literal)和符号引用(Symbolic Reference)。
字面量比较接近于 Java 语言层面的常量概念,如文本字符创,声明为 final 的常量值等。
而符号引用则属于编译原理方面的概念,包括了下面三类常量:
- 类和接口的全限定符(Fully Qualified Name)
- 字段的名称和描述符(Descriptor)
- 方法名称和描述符
常量池内容,格式如下:
1 | cp_info { |
常量池中每一项常量都是一个表结构,每个表的开始第一位是 u1 类型的标志位 tag, 代表当前这个常量的类型。在J DK 1.7 中共有 14 种不同的表结构的类型,如下:
| 类型 | 标志 | 描述 |
|---|---|---|
| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整形字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
| CONSTANT_MothodType_info | 16 | 标志方法类型 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
注意:在这 14 种表结构有一个共同的特点,就是开始的第一位是一个 u1 类型的标志位(tag 就是上表中的标志这一列),代表当前这个常量属于哪种常量类型,下面分析实例的时候会用到。
这 14 种常量类型各自均有自己的结构,下面我们来分析常量池里面的内容。

可以看到常量池计数器后面的第一个 u1 类型是 0x0A 转换成十进制是 10,对应上面 14 中表结构为 CONSTANT_Methodref_info。
在 Java 虚拟机规范中可以看到 CONSTANT_Methodref_info 对应的数据结构为:
1 | CONSTANT_Methodref_info { |
可以看到 CONSTANT_Methodref_info 数据结构中 tag 后面的 class_index、name_and_type_index 都为 u2 类型。

1 | ClassFile { |
class_index、name_and_type_index 都是索引值,它们指向常量池中其他类型的常量。
通过 javap 命令可以看到,常量池中给的第一个数据与我们分析的一致。
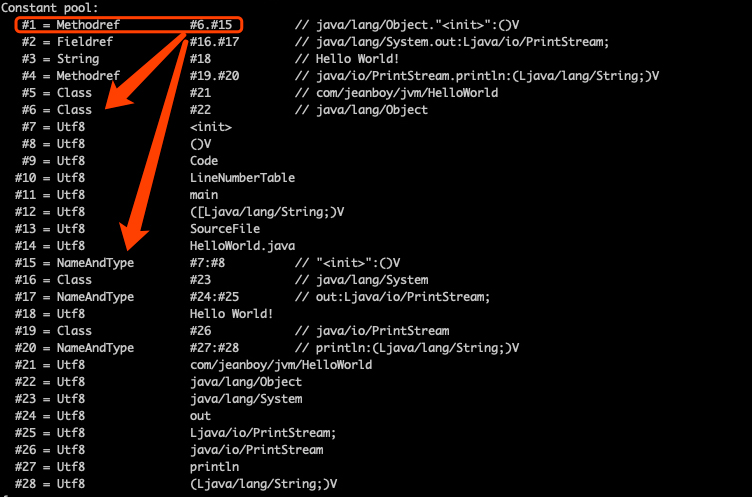
我们接着分析第二个常量,首先取一个 u1 类型为 0x09 转成十进制为 9,对应上面 14 中表结构为
CONSTANT_Fieldref_info。
在虚拟机规范中的 CONSTANT_Fieldref_info 数据结构定义为:
1 | CONSTANT_Fieldref_info { |
可以继续分析出来 class_index 和 name_and_type_index。

1 | ClassFile { |
可以看到与 javap 命令输出的一致。后面的 26 个常量与这两个常量分析方法一致,这里不再赘述。每个常量类型对应的具体数据结构请参阅《Java 虚拟机规范》。
CONSTANT_Utf8_info
在上面的分析中 name_and_type_index 最后都指向了 CONSTANT_Utf8_info 类型的常量。
在虚拟机规范中的 CONSTANT_Utf8_info 数据结构定义为:
1 | CONSTANT_Utf8_info { |
length 值说明了这个 UTF-8 编码的字符串长度是多少字节,它后面紧跟着的长度为 length 字节的连续数据时一个使用 UTF-8 缩略编码表示的字符串。
由于 class 文件中方法、字段等都需要引用 CONSTANT_Utf8_info 类型常量来描述名称,所以 CONSTANT_Utf8_info 类型常量的最大长度也就是 Java 中方法、字段名的最大长度,也就是 u2 类型能表达的最大长度 65535。
所以 Java 程序中如果定义了超过 64KB 英文字符变量或者方法名,将无法编译。
访问标志
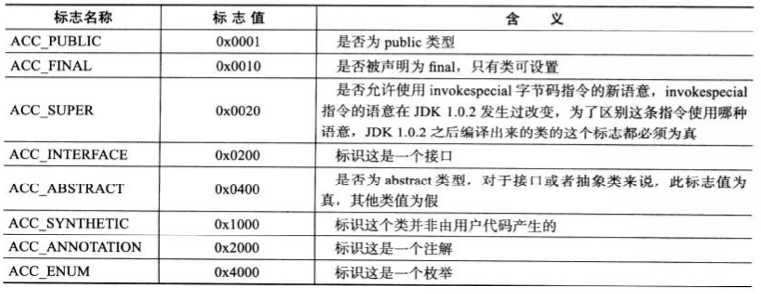
在常量池结束之后,紧接着的两个字节代表访问标志(access_flags),这个标志用于识别一些类或者接口层次的访问信息,包括:这个 class 是类还是接口;是否定义为 public 类型;是否定义为 abstract 类型;如果是类的话,是否被声明为 final 等。
具体的访问标志与含义如下图:
我们来看下常量池后面的内容:

1 | ClassFile { |
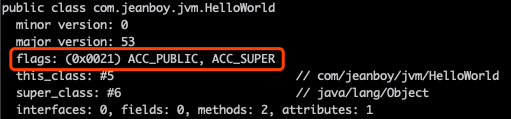
0x0021 什么鬼?上面表中没有这个数据。原来这个值是一个总和,访问标志可能同时有多个。可以算出来 0x0021 对应的是 ACC_PUBLIC 和 ACC_SUPER。
通过 javap 输出的信息,也可以看到是两个访问标志:
类索引、父类索引与接口索引
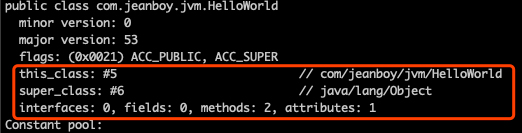
类索引(this_class)和父类索引(super_class)都是一个 u2 类型的数据,接口索引集合(interfaces)是一组 u2 类型的数据集合。

1 | ClassFile { |
所以 this_class:#5、super_class:#6, interfaces_count:0,这里因为 interfaces_count = 0 所以就没有 interfaces 表内容了。
class 文件中由这三项数据来确定这个类的继承关系,类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于 Java 语言不允许多重继承,所以父类索引只有一个,除了 java.lang.Object 之外,所有的 Java 类都有父类,因此除了 java.lang.Object 外,所有的 Java 类的父类索引都不为 0。
接口索引集合用来描述这个类实现了哪些接口,这些被实现的接口将按 implements 语句(如果这个类本身是一个接口,则应当是 extends 语句)后的接口顺序从左到右在接口索引集合中。
字段表
字段表用于描述类或接口中声明的变量,格式如下:
1 | field_info { |
字段访问标识如下:(表中加粗项是字段独有的)
| 标识名 | 标识值 | 解释 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 声明为 public; 可以从包外部访问 |
| ACC_PRIVATE | 0x0002 | 声明为 private; 只有定义的类可以访问 |
| ACC_PROTECTED | 0x0004 | 声明为 protected;只有子类和相同package的类可访问 |
| ACC_STATIC | 0x0008 | 声明为 static;属于类变量 |
| ACC_FINAL | 0x0010 | 声明为 final; 对象构造后无法直接修改值 |
| ACC_VOLATILE | 0x0040 | 声明为 volatile; 不会被缓存,直接刷新到主屏幕 |
| ACC_TRANSIENT | 0x0080 | 声明为 transient; 不能被序列化 |
| ACC_SYNTHETIC | 0x1000 | 声明为 synthetic; 不存在于源代码,由编译器生成 |
| ACC_ENUM | 0x4000 | 声明为enum |
Java 语法中,接口中的字段默认包含 ACC_PUBLIC、ACC_STATIC、 ACC_FINAL 标识。ACC_FINAL、ACC_VOLATILE 不能同时选择等规则。
紧跟其后的 name_index 和 descriptor_index 是对常量池的引用,分别代表着字段的简单名和方法的描述符。
可以看到这里的字段数量为 0。

1 | ClassFile { |
方法表
方法表与字段表格式完全一致,用于描述类或接口中声明的方法,格式如下:
1 | method_info { |
方法访问标识如下:(表中加粗项是方法独有的)
| 标识名 | 标识值 | 解释 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 声明为 public; 可以从包外部访问 |
| ACC_PRIVATE | 0x0002 | 声明为 private; 只有定义的类可以访问 |
| ACC_PROTECTED | 0x0004 | 声明为 protected;只有子类和相同package的类可访问 |
| ACC_STATIC | 0x0008 | 声明为 static;属于类变量 |
| ACC_FINAL | 0x0010 | 声明为 final; 不能被覆写 |
| ACC_SYNCHRONIZED | 0x0020 | 声明为 synchronized; 同步锁包裹 |
| ACC_BRIDGE | 0x0040 | 桥接方法, 由编译器生成 |
| ACC_VARARGS | 0x0080 | 声明为 接收不定长参数 |
| ACC_NATIVE | 0x0100 | 声明为 native; 由非Java语言来实现 |
| ACC_ABSTRACT | 0x0400 | 声明为 abstract; 没有提供实现 |
| ACC_STRICT | 0x0800 | 声明为 strictfp; 浮点模式是FP-strict |
| ACC_SYNTHETIC | 0x1000 | 声明为 synthetic; 不存在于源代码,由编译器生成 |
对于方法里的 Java 代码,进过编译器编译成字节码指令后,存放在方法属性表集合中 code 的属性内。
当子类没有覆写父类方法,则方法集合中不会出现父类的方法信息。
Java 语言中重载方法,必须与原方法同名,且特征签名不同。特征签名是指方法中各个参数在常量池的字段符号引用的集合,不包括返回值。当时 class 文件格式中,特征签名范围更广,允许方法名和特征签名都相同,但返回值不同的方法,也是可以合法地共存于同一个 class 文件中。
可以看到这里有 2 个方法。

1 | ClassFile { |
attribute_info 是属性表,是另外一种结构,我们继续分析属性表内容。
属性表
属性表(attribute_info)在 class 文件、字段表、方法表中都可以携带自己的属性表集合,以用于描述某些场景专有信息。
与其它数据项目要求的顺序、长度、内容不同,属性表集合的要求稍微宽松,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,编译器还可以向属性表中写入自已定义的属性信息,Java 虚拟机能忽略掉它不认识的属性。
下图是 Java 虚拟机规范 一文中预定义的 9 项虚拟机能识别的属性。

对于每个属性,它的名称需要从常量池中引用一个 CONSTANT_Utf8_info 类型的常量来表示,而属性值的结构则是完全自定义的,只需要说明属性所占用的长度即可,一个规范的属性表应该满足下面所示结构。

可以看到:

1 | ClassFile { |
Code 属性
Java 方法内代码经过 javac 编译处理后,最终变成字节码指令存储在 Code 属性内。Code 属性出现在方法表的属性集合中,但并非所有方法表都必须存在这个属性。接口或抽象类的方法就不存在 Code 属性。Code 属性结构如下:
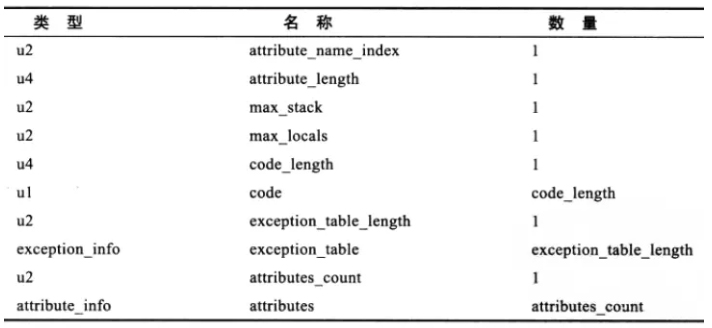
attribute_name_index 是一项指向 CONSTANT_Utf8_info 型常量的索引,常量值固定为 Code。
attribute_length 指示了属性的长度。
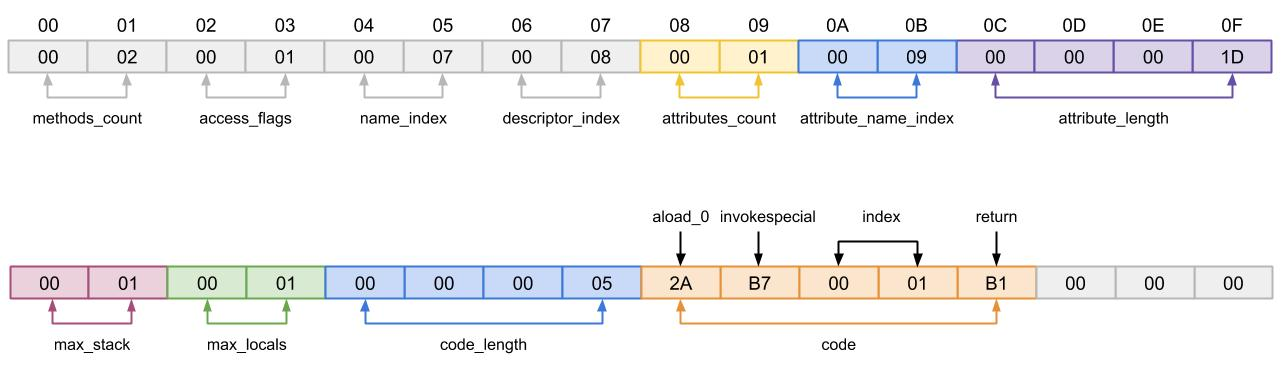
max_stack 代表了操作数栈深度的最大值,在方法执行的任意时刻,操作数栈不会大于这个深度。
max_locals 代表了局部变量所需要的存储空间。max_locals 单位是 slot,slot 是虚拟机为局部变量分配内存所使用的最小单位。
对于byte、char、float、int、short、boolean、reference、return Address 等长度不超过 32 位的数据类型,每个局部变量使用 1 个 slot,而 double 和 long 这两种 64 位数据类型则使用 2 个 slot。
注意:slot 可以重用,当代码执行超出一个局部变量的作用域时,这个局部变量所占用的 slot 就可以被其它局部变量使用。
code_length 和 code 用于存储 Java 源程序编译后生成的字节码指令。code_length 代表字节码长度,code 用于存储字节码指令的一系列字节流。code 由 u1 表示,虚拟机讲到一个字节码时就知道怎么理解,后续带什么参数等等。u1 的取值是 0 到 255,也就是说一共可以表达 255 条指令。
code 有点类似 CPU 上的指令集,例如 + 号会被编译成 iadd 虚拟机字节码指令。
code_length 由一个 u4 表示,理论上最大值是 2^32-1,但虚拟机规范中限制方法不能超过 65535。
1 | ClassFile { |
异常表
异常表就是方法中的异常处理内容,try catch 代码块。它的结构如下所示:
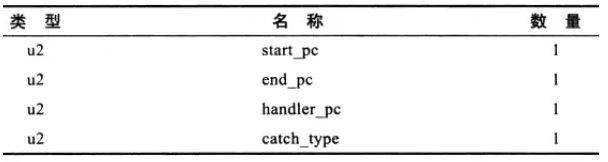
它表示,如果字节码从 start_pc 行到 end_pc 行之间出现类型为 catch_type 或其子类的异常,则转到 handler_pc 行继续处理。

1 | ClassFile { |
Exceptions 属性
Exceptions 是在方法表中与 Code 属性平级的一项属性,与异常表不一样,异常表是 Code 的下级属性。Exceptions 属性的作用是列举出方法中可能抛出的受查异常,也就是 throws 关键字后列表的异常,它的结构表如下:

number_of_exceptions 项表示方法有可能抛出多少种异常,每一种异常由一个 exception_index_table 项表示,exception_index_table 是一个指向常量池中 utf8 类型的索引。
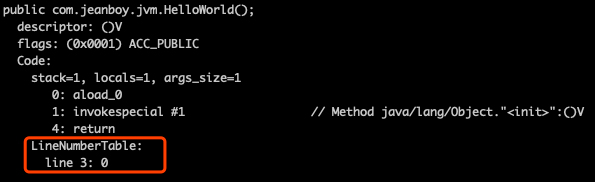
LineNumberTable 属性
LineNumberTable 属性用于描述 Java 源码行号与字节码行号之间的对应关系。它不是必须属性,如果不生成它,那么产生异常后,堆栈中将不会显示出错的行号,并且在调试时也无法在源码中设置断点。
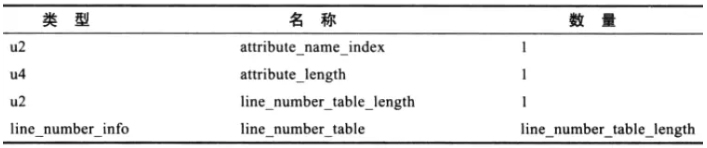
line_number_table 是一个数量为 line_number_table_length、类型为 line_number_info 的集合,line_number_info 表包括了 start_pc 和 line_number 两个 u2 数据项,前者是字节码行号,后者 是 Java 源码行号。

1 | ClassFile { |
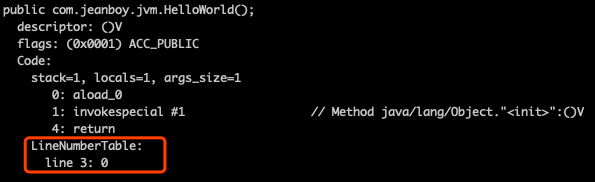
通过 javap 命令可以看到对应内容:
LocalVariableTable 属性
LocalVariableTable 用于描述栈桢中局部变量表中的变量与 Java 源码中定义的变量之间的关系。也不是必须的,它的结构如下:
其中 local_variable_info 项目代表了一个栈桢与源码中局部变量的关联,结构如下:

start_pc 和 length 属性分别代表这个局部变量的生命周期的字节码偏移量及其作用范围覆盖的长度,两者结合起来就是这个局部变量在字节码之中的作用域范围。
name_index 和 descriptor_index 都是指向常量池中 utf8 类型的常量,分别代表局部变量的名称及局部变量的描述符。
index 是这个局部变量在栈桢局部变量表中 slot 的位置,如果是 64 位类型,则它占用的 slot 为 index 和 index + 1的两个位置。
SourceFile 属性
SourceFile 属性,用于记录 class 文件的源码文件名称。


1 | ClassFile { |
总结
完整的结构:
1 | ClassFile { |
到这里,大家对字节码文件应该已经有了一个完整的了解,内容比较多,建议大家通过 javap 命令来理解。
参考资料
- 《深入理解 Java 虚拟机》
- 《Java 虚拟机规范 SE 8 版》
 wechat
wechat alipay
alipay




