细说Mmongo ES 数据过期机制
数据过期在redis上非常容易实现,mongo中可使用TTL索引实现类似的功能。
Mongo数据过期
TTL索引
TTL是mongo 中的一种特殊的单字段索引,可以支持文档在一定时间之后自动删除,字段类型必须是 ISODate类型或者包含有ISODate类型的数组,创建TTL索引和创建普通索引的方法一样,只是多加了一个属性而已:
1 | db.collection(集合).createIndex({create_time(ISODate类型字段):1(正序),{expireAfterSeconds:过期时间,单位秒},{backgroud(后台执行):true}}) |
TTL索引包含以下特点:
- _id字段不支持TTL索引
- 如果索引字段是数组,并且字段中多个日期值,则mongo使用数组中最早的日期值来计算到期阈值
- 如果文档中的索引字段不是ISODate 类型或者不包含ISODate 类型的数组,则文档不会过期
- 如果某个字段已经存在非TTL索引,则无法在同一字段上创建TTL索引
另外一点,如果想实现如同redis一样动态设置过期时间,可以在集合中增加一个TTL索引,并指定其过期时间为0,表示过期时间由索引字段的时间来决定。
与redis的自动过期自动删除数据相比,mongo的自动删除数据并不能保证原子性,其原因在于TTL索引不保证数据在过期后立即删除,而是起一个线程定时(默认60s)扫描并删除过期数据,该删除动作会根据mongo实例的负载情况做出调整,如果负载很高,可能会稍微延迟一段时间再删除,所以过期数据可能会比过期时间多存在一段时间。还有一个需要注意的地方,在副本集中,TTL后台线程只会删除主节点的过期数据,从节点从主节点中复制删除操作。
实操
1 | -- part1 创建TTL索引 60s 过期 |
ES数据过期
ES在 6.6 以后推出了 Index Lifecycle Management ,可对索引生命周期进行管理,新版本默认开启了ILM 。
IML
ILM 生命周期主要定义了四个阶段:
- Hot :通常是用来放最新的数据,写入、可以查询
- Warm : 数据保存后,不在写入时,但是会常常的查询,通常会放在这个阶段,不能写入,可以查询
- Cold : 数据存放时间很久,不常使用,但是希望需要用的时候能马上能用,可以接受速度慢一些,放在这一阶段,不能写入,可以查询(但是较慢)
- Delete : 从ES中删除

上图可以解释数据随着时间变化,不断产生新的Index,并且随着时间变化,逐渐移动到下一个阶段中。
在 IML 中,可以建立一个 Policy 来指定想要设定哪些阶段,以及每个阶段要进行的动作(Action), IML 中可进行的动作如下:
| Action | 含义 |
|---|---|
| Rollover | 当Index 达到 一定大小、文档个数、文档存放时间 时,自动建立新的 Index 来存放新进来的文档,不会让某 Index一直无限增长下去。这个动作可以针对 Index Alias 或者 Data Stram 进行设定 |
| Shrink | 将多个Shard 的Index 转成较少 Shard 数量的Index |
| Force merge | 将一个 Shard 中的 Segment Files 进行合并,可以释放出被删掉的文件在原先 read-only 的 Segment File 所占用的空间,也能加快查询的速度 |
| Freeze | 将很少使用的Index,以尽量不使用 heap size 的方式来存放 |
| Delete | 删除 Index |
| Allocate | 指定 Index replica 的数量,以及指定Index 可以被放在哪些 shards 的规则 |
| Set Priority | 指定 Index replica 的数量,以及指定Index 可以被放在哪些 shards 的规则 |
| Set Priority | 指定Index的处理先后权,也就是当 node重新启动的时候,较高权限的Index会先被 recover 而先会到可用的状态 |
| Unfollow | 将 Cross Cluster Replication 机制中,会 follow 的index 给取消 follow 。在Rollover ,Shrink 处理时会自动执行这个动作 |
| Wait for snapshot | 等到 Snapshot 完成后才能删除Index |
ILM 生命周期每个阶段可以进行的动作有哪些:
| IML生命周期 | 可进行的动作 |
|---|---|
| Hot | Force merge,Rollover,Set priority, Unfollow |
| Warm | Allocate, Force merge, Read only, Set priority, Shrink, Unfollow |
| Cold | Allocate, Freeze, Set priority, Unfollow |
| Delete | Delete, Wait for snapshot |
那么如何配置 ILM 呢?
实操
我们可以从Kibana 的Stack Management进行设置
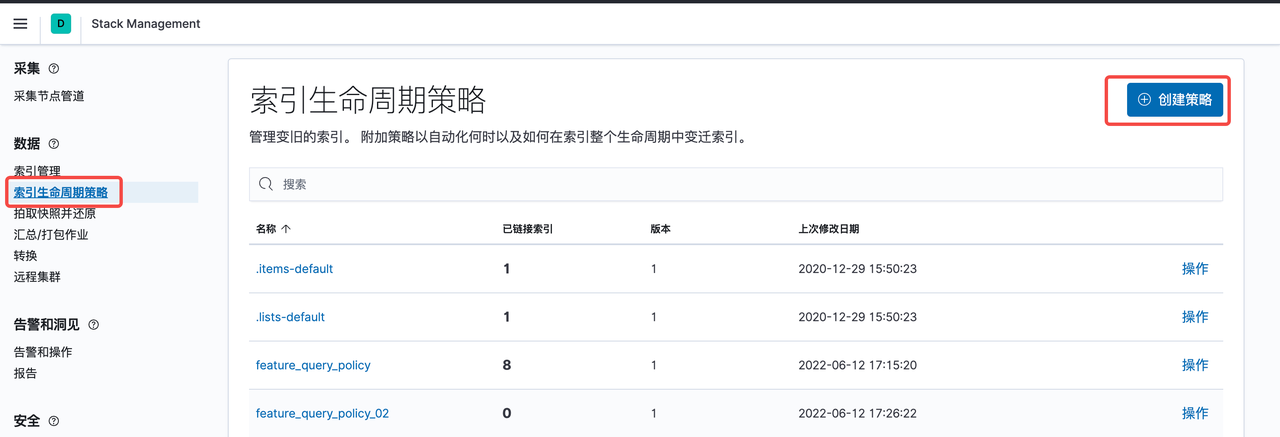
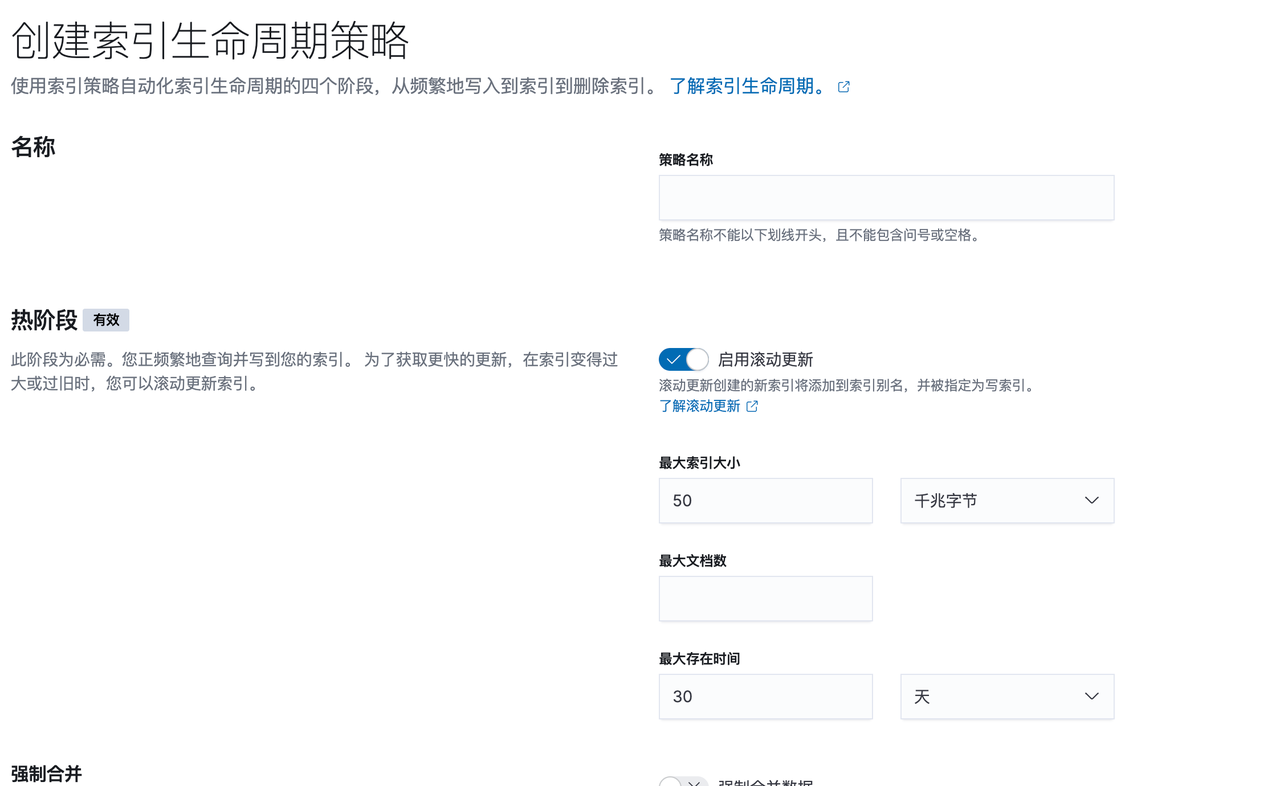
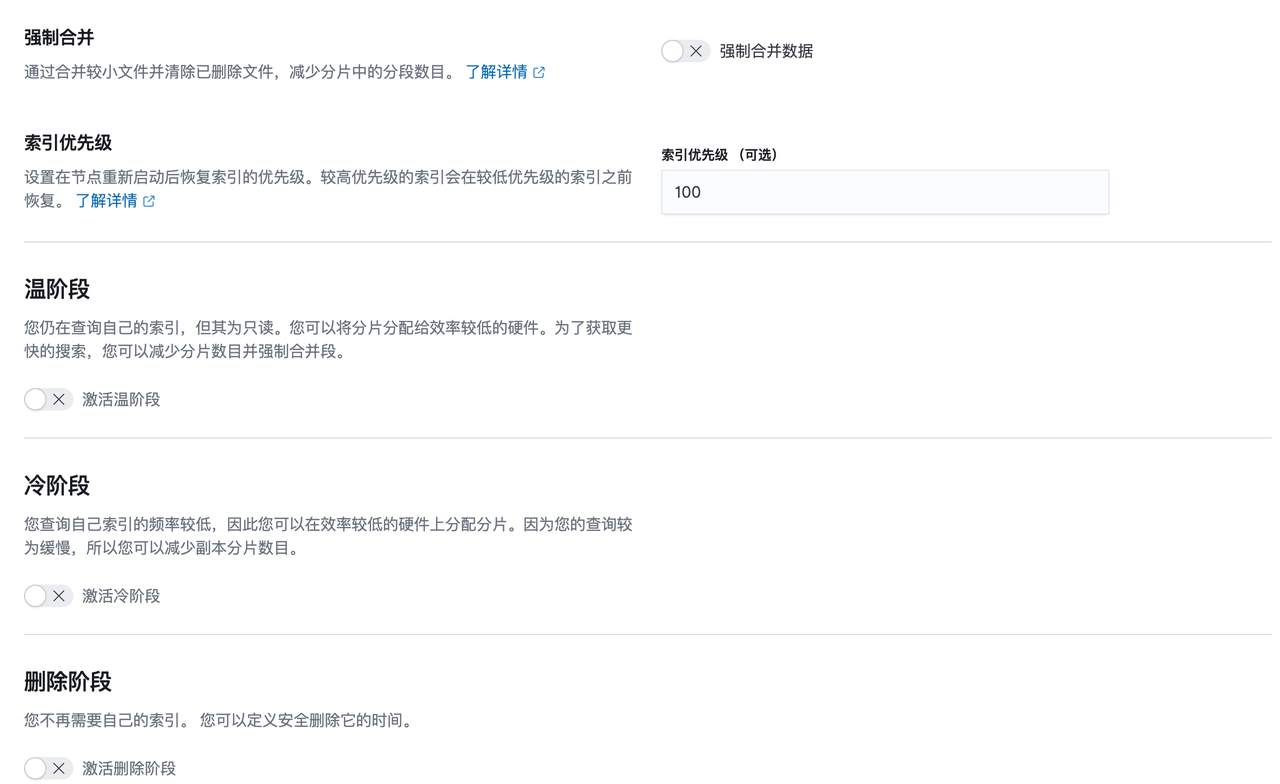
设置好 Index Lifecycle Policy 后,需要将策略添加到索引模板

绑定好模板后,当新的Index被建立时,就会自动套用刚刚创建的生命周期管理机制。关于模板可以参考 Index templates | Elasticsearch Guide [7.10] | Elastic。若想知道某个 Index ,Index Alias 所对应的 Index Lifecycle Policy 执行情况,目前在哪个阶段,可以通过 Explain Lifecyle API 来查看:
1 | GET my-index-000001/_ilm/explain |
更多API可以参考 Explain lifecycle API | Elasticsearch Guide [7.9] | Elastic
参考资料
TTL 索引
ILM: Manage the index lifecycle | Elasticsearch Guide [7.9] | Elastic
 wechat
wechat alipay
alipay




