Java 线程池原理分析
简介
线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销。在应用上,线程池可应用在后端相关服务中。比如 Web 服务器,数据库服务器等。以 Web 服务器为例,假如 Web 服务器会收到大量短时的 HTTP 请求,如果此时我们简单的为每个 HTTP 请求创建一个处理线程,那么服务器的资源将会很快被耗尽。当然我们也可以自己去管理并复用已创建的线程,以限制资源的消耗量,但这样会使用程序的逻辑变复杂。好在,幸运的是,我们不必那样做。在 JDK 1.5 中,官方已经提供了强大的线程池工具类。通过使用这些工具类,我们可以用低廉的代价使用多线程技术。
线程池作为 Java 并发重要的工具类,在会用的基础上,我觉得很有必要去学习一下线程池的相关原理。毕竟线程池除了要管理线程,还要管理任务,同时还要具备统计功能。所以多了解一点,还是可以扩充眼界的,同时也可以更为熟悉线程池技术。
继承体系
线程池所涉及到的接口和类并不是很多,其继承体系也相对简单。相关继承关系如下: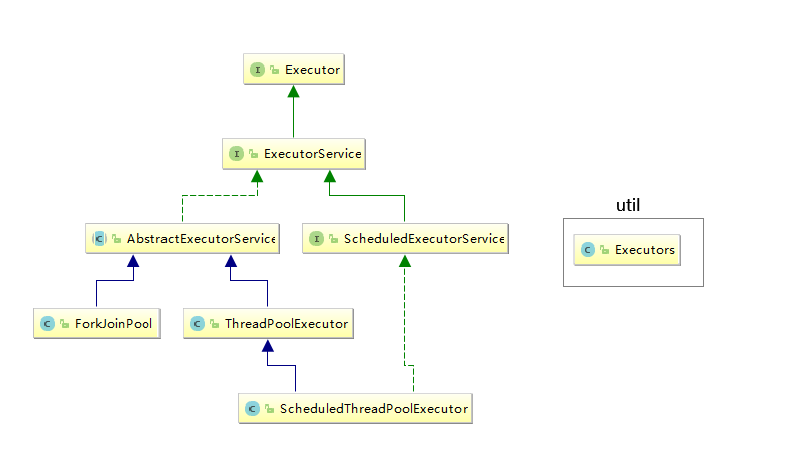
如上图,最顶层的接口 Executor 仅声明了一个方法execute。ExecutorService 接口在其父类接口基础上,声明了包含但不限于shutdown、submit、invokeAll、invokeAny 等方法。至于 ScheduledExecutorService 接口,则是声明了一些和定时任务相关的方法,比如 schedule和scheduleAtFixedRate。线程池的核心实现是在 ThreadPoolExecutor 类中,我们使用 Executors 调用newFixedThreadPool、newSingleThreadExecutor和newCachedThreadPool等方法创建线程池均是 ThreadPoolExecutor 类型。
原理分析
核心参数分析
核心参数简介
核心实现即 ThreadPoolExecutor 类。该类包含了几个核心属性,这些属性在可在构造方法进行初始化。在介绍核心属性前,我们先来看看 ThreadPoolExecutor 的构造方法,如下:
1 | public ThreadPoolExecutor(int corePoolSize, |
如上所示,构造方法的参数即核心参数,这里我用一个表格来简要说明一下各个参数的意义。如下:
| 参数 | 说明 |
|---|---|
| corePoolSize | 核心线程数。当线程数小于该值时,线程池会优先创建新线程来执行新任务 |
| maximumPoolSize | 线程池所能维护的最大线程数 |
| keepAliveTime | 空闲线程的存活时间 |
| workQueue | 任务队列,用于缓存未执行的任务 |
| threadFactory | 线程工厂。可通过工厂为新建的线程设置更有意义的名字 |
| handler | 拒绝策略。当线程池和任务队列均处于饱和状态时,使用拒绝策略处理新任务。默认是 AbortPolicy,即直接抛出异常 |
线程创建规则
在 Java 线程池实现中,线程池所能创建的线程数量受限于 corePoolSize 和 maximumPoolSize 两个参数值。线程的创建时机则和 corePoolSize 以及 workQueue 两个参数有关。
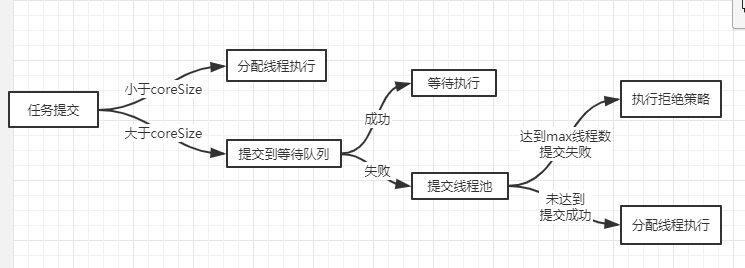
资源回收
考虑到系统资源是有限的,对于线程池超出 corePoolSize 数量的空闲线程应进行回收操作。进行此操作存在一个问题,即回收时机。目前的实现方式是当线程空闲时间超过 keepAliveTime 后,进行回收。除了核心线程数之外的线程可以进行回收,核心线程内的空闲线程也可以进行回收。回收的前提是allowCoreThreadTimeOut属性被设置为 true,通过public void allowCoreThreadTimeOut(boolean) 方法可以设置属性值。
排队策略
当线程数量大于等于 corePoolSize,workQueue 未满时,则缓存新任务。这里要考虑使用什么类型的容器缓存新任务,通过 JDK 文档介绍,我们可知道有3中类型的容器可供使用,分别是同步队列,有界队列和无界队列。对于有优先级的任务,这里还可以增加优先级队列。以上所介绍的4中类型的队列,对应的实现类如下:
| 实现类 | 类型 | 说明 |
|---|---|---|
| SynchronousQueue | 同步队列 | 该队列不存储元素,每个插入操作必须等待另一个线程调用移除操作,否则插入操作会一直阻塞 |
| ArrayBlockingQueue | 有界队列 | 基于数组的阻塞队列,按照 FIFO 原则对元素进行排序 |
| LinkedBlockingQueue | 无界队列 | 基于链表的阻塞队列,按照 FIFO 原则对元素进行排序 |
| PriorityBlockingQueue | 优先级队列 | 具有优先级的阻塞队列 |
拒绝策略
线程数量大于等于 maximumPoolSize,且 workQueue 已满,则使用拒绝策略处理新任务。Java 线程池提供了4中拒绝策略实现类,如下:
| 实现类 | 说明 |
|---|---|
| AbortPolicy | 丢弃新任务,并抛出 RejectedExecutionException,阻止系统正常巩工作 |
| DiscardPolicy | 不做任何操作,直接丢弃新任务,若允许任务丢失,可能是最好的一种方案 |
| DiscardOldestPolicy | 丢弃队列队首的元素,并执行新任务 |
| CallerRunsPolicy | 只要线程池未关闭,该策略直接在调用者线程中运行当前被拒绝的任务。这样做不会真的丢弃任务,但是任务提交线程的性能有可能会急剧下降 |
我们也可以通过方法public void setRejectedExecutionHandler(RejectedExecutionHandler)修改线程池决绝策略。
重要操作
优化线程池数量
线程池的大小对系统的性能有一定的影响。过大或者过小的线程数量都无法发挥最优的系统性能,但是线程池的确定也不需要做得非常精确。在《Java Concurrency in Practice 》一书中给了一个估计线程池大小的经验公式:
$$
Ncpu = CPU的数量
$$
$$
Ucpu = 目标CPU的使用率,0≤Ucpu≤1
$$
$$
W/C = 等待时间与计算时间的比率
$$
$$
Nthread = Ncpu × Ucpu ×(1+W/C) = Ncpu × Ucpu + Ncpu × Ucpu × W/C
$$
假设目标CPU 使用率100%,
当任务为IO密集型的时候 Nthread ≈ 2Ncpu (IO密集型,需考虑IO等待时间,线程上下文切换时间影响较小)
当任务为计算密集型的收 Nthread ≈ Ncpu (计算密集型减少线程上下文切换)
在Java中,可以通过:Runtime.getRuntime().availableProcessors()获取CPU数量。
关闭线程池
我们可以通过shutdown和shutdownNow两个方法关闭线程池。两个方法的区别在于,shutdown 会将线程池的状态设置为SHUTDOWN,同时该方法还会中断空闲线程。shutdownNow 则会将线程池状态设置为STOP,并尝试中断所有的线程。中断线程使用的是Thread.interrupt方法,未响应中断方法的任务是无法被中断的。最后,shutdownNow 方法会将未执行的任务全部返回。
调用 shutdown 和 shutdownNow 方法关闭线程池后,就不能再向线程池提交新任务了。对于处于关闭状态的线程池,会使用拒绝策略处理新提交的任务。
几种线程池
在阿里巴巴Java开发手册中明确指出禁止使用Executors 工具类创建线程。
1 | // Executors.newSingleThreadExecutor() |
Executors 各个方法的弊端:
1)newFixedThreadPool 和 newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至 OOM。
2)newCachedThreadPool 和 newScheduledThreadPool:
主要问题是线程数最大数是 Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至 OOM。
 wechat
wechat alipay
alipay




